vision transformer
Vision Transformer
Transformer

自注意力机制(self-attention)
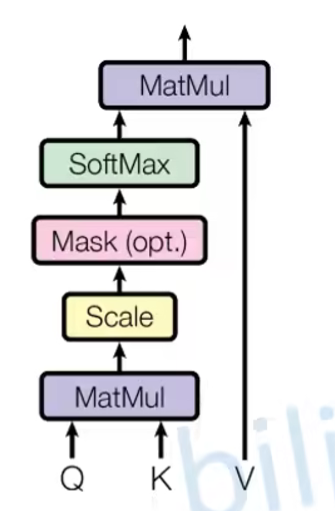
计算注意力分数使用的是缩放点积模型。
Scale(缩放)的作用:由于进行点乘后的数值很大,导致通过的softmax后梯度变得很小
多头注意力机制(Multi-Head Attention)
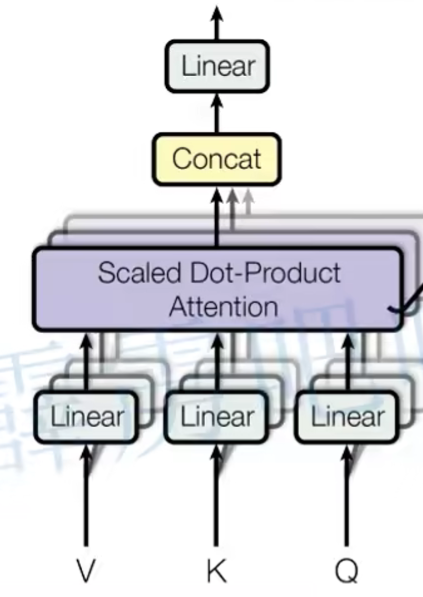
tips:
- 每个Patch数据通过映射得到一个长度为768的token向量,即[16, 16, 3] -> [768]
VIT 和 transformer的区别
Vision Transformer(ViT)是一种将Transformer架构应用于计算机视觉领域的模型,它与传统的Transformer模型在某些方面有所不同。以下是ViT与标准Transformer的一些主要区别:
输入数据结构:
- Transformer:通常用于处理序列数据,如文本,其中输入是一系列离散的标记或单词。
- ViT:专门用于处理图像数据,将图像分割成固定大小的块(patches),然后将这些块作为序列数据输入到Transformer中。
位置编码:
- Transformer:在NLP中,位置编码用于保持序列中单词的顺序信息,因为Transformer本身不具备捕捉序列顺序的能力。
- ViT:同样使用位置编码,但是是为了在图像块的序列中保留空间位置信息,因为图像块在原始图像中的位置对于理解图像内容是重要的。
应用领域:
- Transformer:最初设计用于NLP任务,如机器翻译、文本摘要、语言建模等。
- ViT:主要应用于计算机视觉任务,如图像分类、目标检测等。
架构:
- Transformer:由编码器和解码器组成,常用于序列到序列的任务。
- ViT:通常只使用编码器部分,因为许多视觉任务(如图像分类)不需要解码器。
注意力机制:
- Transformer:在编码器中使用自注意力机制来处理序列内的依赖关系。
- ViT:在处理图像块序列时也使用自注意力机制,但这些块之间的关系与文本中的单词关系不同,它们代表了图像中的局部区域。
训练策略:
- Transformer:在NLP中,Transformer模型通常在大规模文本语料库上进行预训练,然后在特定任务上进行微调。
- ViT:在视觉任务中,ViT也可以在大规模图像数据集上进行预训练,以学习丰富的视觉特征。
ViT证明了Transformer架构不仅在处理文本数据时有效,也可以在图像识别等视觉任务中取得优异的性能。通过将图像分解为序列化的块,并利用Transformer的自注意力机制,ViT能够捕捉图像的全局和局部特征,从而在多个视觉任务中实现先进的性能。
为什么许多视觉任务(如图像分类)不需要解码器
在视觉任务中,尤其是图像分类任务,通常不需要解码器的原因与这些任务的性质和目标有关。以下是几个关键点来解释为什么许多视觉任务不需要解码器:
任务定义:
- 图像分类任务的目标是识别图像中的主要对象并将其分类到预定义的类别中。这是一个直接的映射过程,从输入图像到输出类别标签,不需要生成或重建图像。
- 相比之下,序列到序列的任务(如机器翻译或文本摘要)需要解码器来生成或重建序列。解码器在这些任务中用于将编码器的输出转换为有意义的输出序列。
模型结构:
- 对于图像分类,可以使用单个流的网络结构,其中输入图像通过一系列层(如卷积层、池化层、全连接层或Transformer编码器层)直接映射到类别标签。
- 解码器通常用于需要从固定大小的表示中重建或生成数据的任务。在图像分类中,不需要从图像中重建或生成任何内容,因此不需要解码器。
输出形式:
- 图像分类的输出是离散的类别标签,这可以通过 softmax 层直接从模型的最终层输出得到。
- 解码器在生成任务中用于产生连续的输出,如文本或时间序列数据。在图像分类中,不需要这样的连续输出生成过程。
计算效率:
- 在图像分类中,省略解码器可以减少模型的复杂性和计算成本,因为不需要额外的网络层来处理输出序列。
- 解码器的引入通常会增加模型的参数数量和计算负担,这对于图像分类这样的简单映射任务来说是不必要的。
自注意力机制:
- 在使用Transformer或ViT等模型时,编码器中的自注意力机制已经能够捕捉图像中的全局和局部特征,足以进行有效的分类。
- 解码器在自注意力模型中通常用于处理序列生成任务,如语言模型或机器翻译,这些任务需要考虑序列的顺序性和上下文信息。
任务复杂性:
- 图像分类通常被认为是一个相对简单的任务,至少在不需要详细理解图像内容(如物体之间的关系或场景的复杂性)的情况下。
- 更复杂的视觉任务,如图像描述生成或视觉问答,可能需要解码器来生成详细的输出。
总的来说,图像分类等视觉任务不需要解码器,因为它们的目标是识别和分类,而不是重建或生成图像内容。这使得模型可以专注于从图像中提取特征并进行分类,而无需额外的解码过程。
MLP
Transformer Block中的MLP
在自注意力机制之后,通常会有一个简单的MLP,其作用是对自注意力机制的输出进行进一步的非线性变换。
这个MLP通常包含两个线性变换(FC), 它们之间有一个激活函数(通常是GELU激活函数)。MLP的输入是自注意力机制的输出,输出是经过MLP变换后的特征,这些特征将被送入下一个Transformer块或最终的分类头部。
分类头部中的MLP
在ViT的末尾,特征图经过一个分类头部来生成最终的分类结果。在ViT的早期版本中,分类头部可能仅仅是一个线性层,它将Transformer的输出特征映射到类别数量的维度上。然而,现代的ViT变体通常在分类头部使用一个或多个MLP层,以提供更复杂的非线性变换能力。
这些MLP层允许模型在最终的分类决策中捕捉更高层次的特征交互,有助于提高分类的准确性。